در این نوشتار با مفاهیم مهمی که برای تحلیل دینامیک بیماری و نتایج آن کلیدی هستند آشنا میشوید.
R0 (قابلیت انتقال بیماری): این پارامتر یکی از مهمترین عوامل تعیینکننده در توانایی بیماری برای گسترش سریع و تبدیل شدن به اپیدمی است.
قابلیت انتقال بیماری به معنای توانایی انتقال بیماری از یک فرد مبتلا به افراد دیگر در جامعهای که تمام افراد مستعد ابتلا به این بیماری هستند. در حال حاضر این پارامتر برای بیماری کرونا بین ۲ و ۳ تخمین زده شده است. به این معنا که هر فرد بیمار در طول دوره بیماری امکان انتقال به دو تا سه نفر را دارد. این عدد برای افرادی که با افراد زیادی در ارتباط هستند و یا زیاد سفر میکنند بیشتر است و برای افرادی که کمتر ارتباط دارند کمتر است. لذا این عدد در نتیجه عکسالعمل مردم به بیماری تغییر میکند. مثلا کاهش برهمکنشها به کاهش این عدد میانجامد.
زمانی که این پارامتر به ۱ برسد، اپیدمی تحت کنترل در میآید. به این معنا که یا افراد از طریق ایمنی یا واکسن به بیماری مبتلا نمیشوند، یا تعداد افراد مبتلا در جامعه به حدی پایین است که بیماری به افراد زیادی انتقال پیدا نمیکند.
دوره کمون (نهفته): فاصله زمانی از روزی که فرد به بیماری مبتلا می شود تا زمانی که نشانههای بیماری در فرد پیدا میشود. در بسیاری از بیماریهای عفونی مانند کرونا، افراد ممکن است در زمانی که هنوز نشانههایی از بیماری نیست نیز بیماری را به دیگران منتقل کنند.
تخمینهای موجود طول این دوره را ۳ تا ۱۴ روز از زمان ابتلا به بیماری نشان میدهند. این دوره نسبتا طولانی باعث میشود که بسیاری از افراد بدون اینکه متوجه باشند بیماری را به دیگران منتقل کنند. یکی از دلایل قرنطینه افراد مشکوک پیشگیری از این اتفاق است.
دوره بیماری با علائم: اغلب افرادی که به بیماری مبتلا میشوند، نشانههای بیماری را تجربه میکنند. در مورد کرونا، اغلب افراد نشانههای ضعیفی را تجربه میکنند که فقط مختص به کرونا نیست. این نشانهها شامل تب، احساس خستگی، و سرفه است. حدود ۱۰ تا ۲۰% افراد مبتلا، نشانههای وخیم بیماری را تجربه میکنند. این نشانهها شامل تنگی نفس، ذاتالریه، و در موارد شدیدتر شوک هست که این افراد احتیاج به بستری شدن در آی سی یو را دارند. بر مبنای مطالعات انجام شده طول در بیماری کرونا تا درمان کامل میتواند تا ۲۲ روز باشد.
درصد مرگ و میر: در صد مرگ و میر هر بیماری با تقسیم تعداد افرادی که در اثر بیماری جان خود را از دست دادهاند به تعداد افرادی که به بیماری مبتلا شدهاند محاسبه میشود. در مورد بیماری کرونا، این عدد با توجه به میزان مواردِ گزارش شده تا به حال حدود ۲% تخمین زده شده است. نکتهای که باید به آن توجه کرد این است که تعداد افراد مبتلا که تابحال گزارش شده است با احتمال قریب به یقین از تعداد مبتلایان کمتر است. دلیل این مشاهده درصد بالای مبتلایانی است که نشانههای خفیف دارند (بیش از ۴۰%) و احتمال اینکه به مراکز بهداشتی برای آزمایش و تشخیص مراجعه نکنند بالاست. بنابرین این افراد در آمارها محاسبه نمیشوند. با توجه به مورد گفته شده. درصد مرگ و میر ناشی از بیماری کرونا بین ۰.۵% و ۲% تخمین زده میشود.
چه افرادی در مرز خطر بیشتر مرگ و میر در اثر ویروس کرونا هستند؟
مطالعات نشان داده اند که سن بالای افراد و ابتلا به سایر بیماریها مانند بیماریهای قلبی، دیابت، فشار خون بالا، بیماریهای تنفسی، و سرطان از عواملی هستند که ریسک مرگ و میر را در افراد مبتلا بالا میبرند. با این حال درصدِ کمی از مرگ و میر در میان افرادی که مبتلا به بیماریهای مزمن نبودهاند هم مشاهده شده است. نمودارهای زیر نتایج مطالعات اپیدمیولوژی بر روی گروه بزرگی از افرادی در چین است که جان خود را در اثر بیماری از دست داده اند.
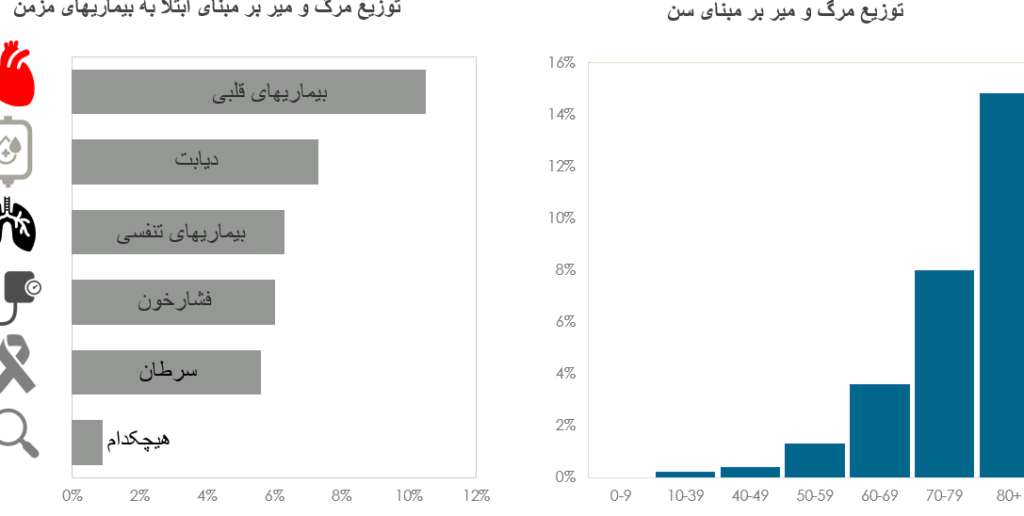
نمودارهای بالا توزیع مرگ و میر بیماران براساس سن و ابتلا به بیماریهای مزمن را نشان میدهند. این اطلاعات بر مبنای مطالعات مرکز کنترل و پیشگیری بیماریها در چین بر روی بیش از ۷۰،۰۰۰ بیمار (تا تاریخ ۲۲ بهمن ۱۳۹۸) انجام شده است. گزارش کامل را در این لینک میتوانید مطالعه کنید.